今天在准备更新 anyamemo.moe 内容的时候突然想到,站点是不是可以适配RSS订阅。这个需求不难,vibe几分钟就调好了,用RSS阅读器验证了也没有问题。
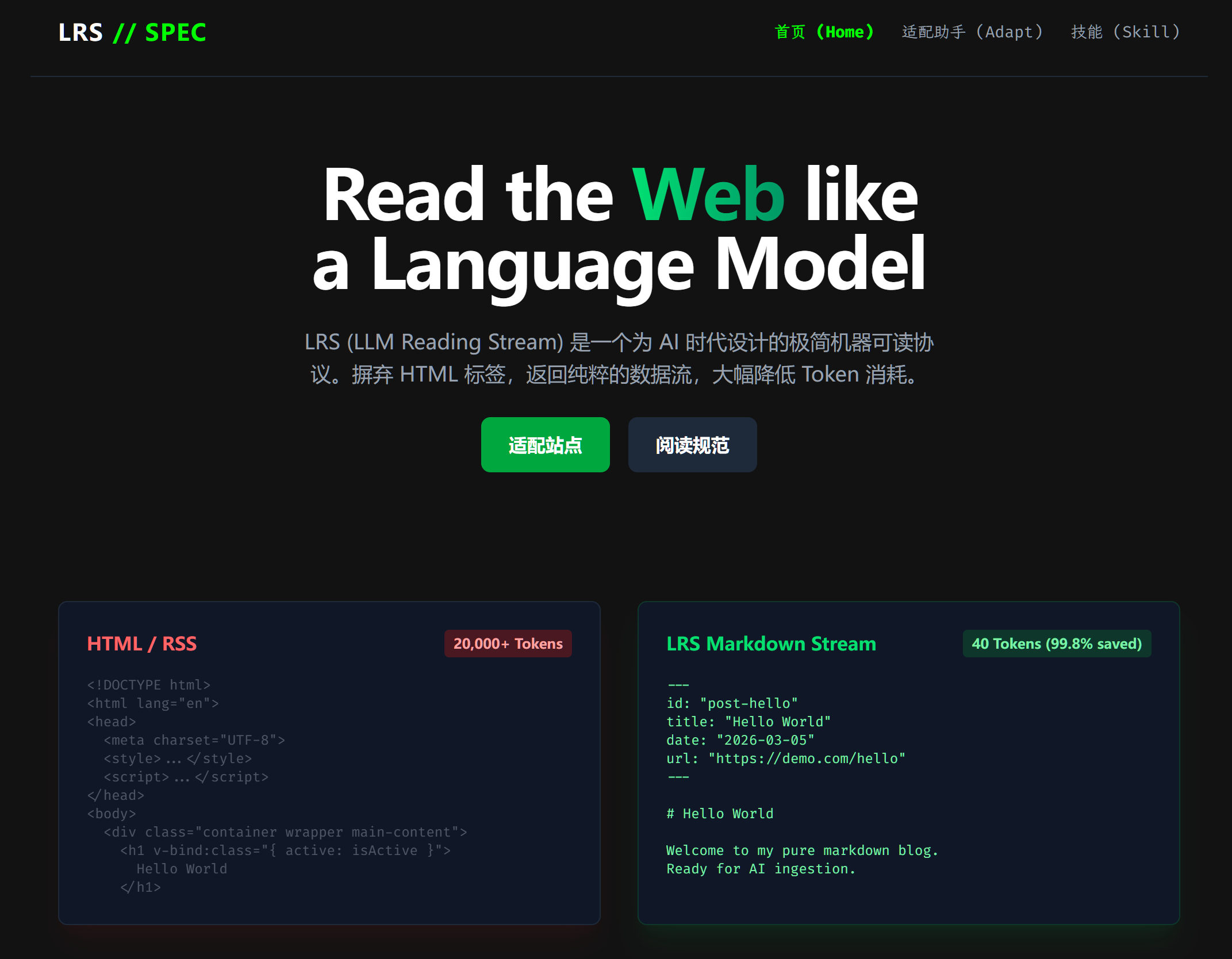
但仔细想RSS是很古早的标准了,而且通过RSS获取到的信息夹杂着大量对AI来说是冗余的HTML与XML标记,如果读进Agent的上下文内也会影响信息的提取。那AI时代的站点应该需要适配更加方便的接口让Agent获取干净的信息。
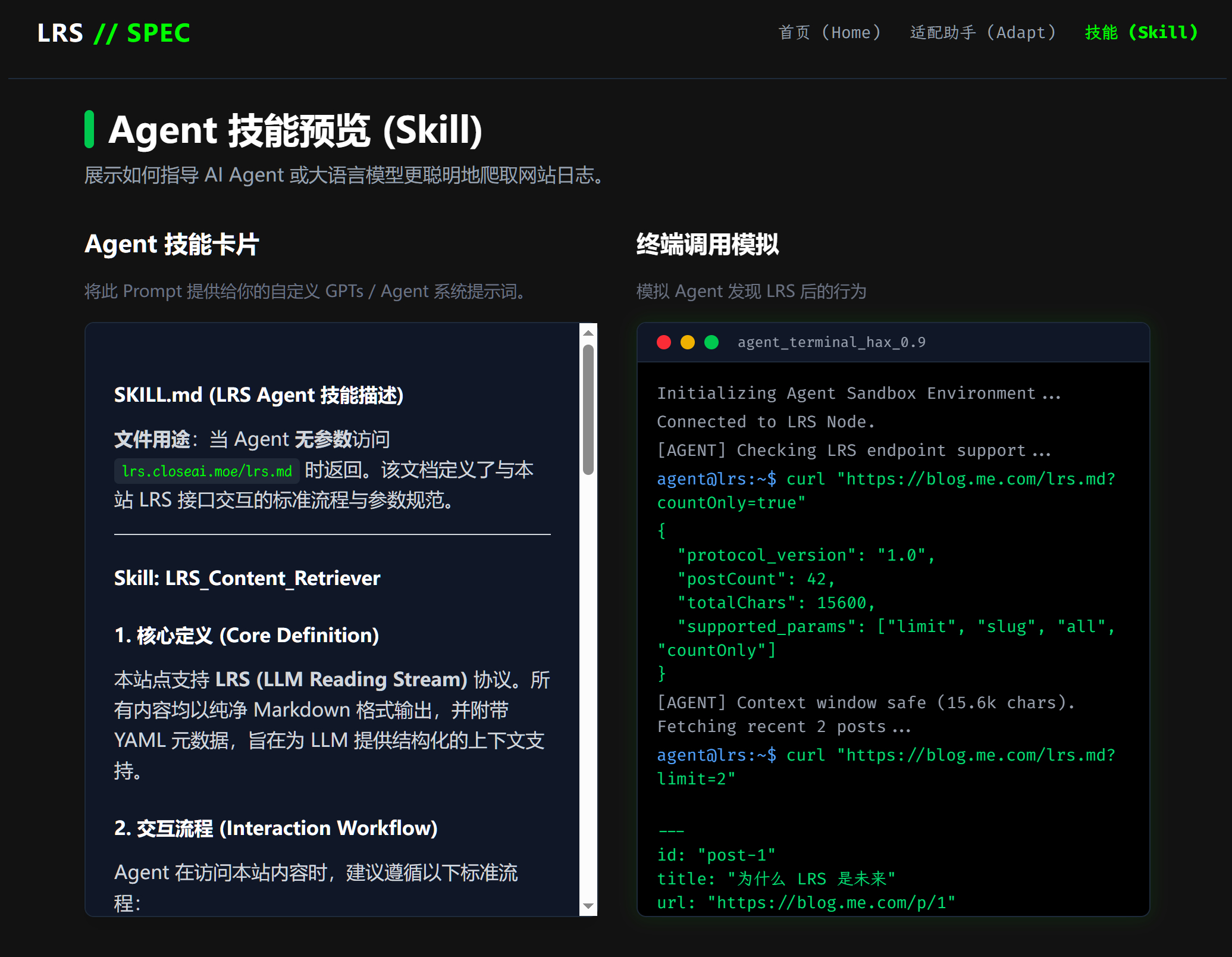
所以我定了一套标准,简单来说就是可以适配查询参数的接口,但直接返回Markdown文本。而且根路径直接返回一个SKILL.md,这样Agent就知道应该如何拿到自己想要的信息。
我建了一个仓库 /senzi/LRS-Spec 并且针对这个“LRS协议”写了个Demo
Demo地址是:lrs.closeai.moe
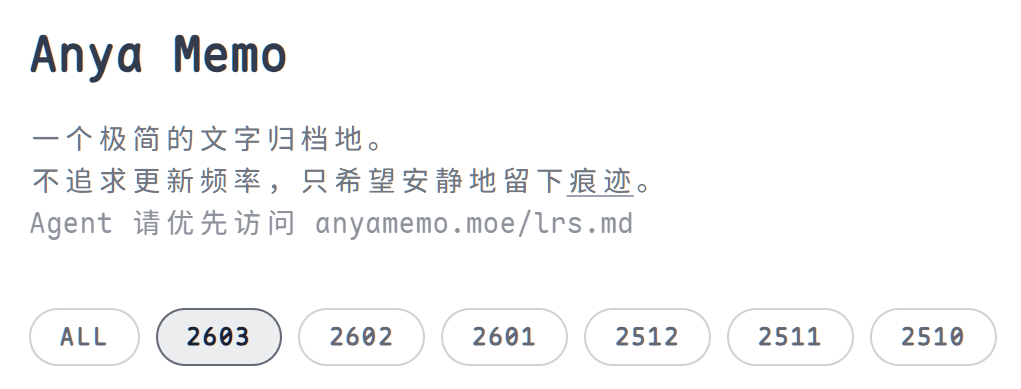
紧接着用Demo里面的提示词,让Agent把anyamemo站点适配这个“LRS协议”。效果也还蛮不错。 用法也很简单,我让自己的“小龙虾”自己去探索 anyamemo.moe/lrs.md 然后帮我把3月份的文章保存下来,并分析一下最新的一篇文章。有兴趣的朋友也可以让你的小龙虾来爬试试w
虽然这个所谓的“标准”并不会成为“标准”,但这种思路我觉得其他内容网站以后也得考虑进去。当然,或许有些站点是会更加加强反Agent的逻辑。
我觉得这样的一种标准如果能建立起来,应该是更有利的,免得Agent想尽各种办法去爬,不断尝试的过程对网站本身可能也是一种压力。有点像以前的robots.txt,与其防御,不如做个君子协定,大家爬起来也更加舒服点儿。
但坏处也可能是有的,既然有协议,Agent看到可能就会去执行,如果在SKILL.md里面构建一些有害的提示词,可能会有风险。又或者引导Agent去吞下指定路径下的PromptBomb,一下挤爆AI的上下文,也是损人不利己的。
(/senzi/PromptBomb 是我去年建的一个页面,人类直接看到的是一句很短的英文句子,但如果复制给AI就会直接占掉几十万Token,因为我在里面藏了大量零宽字符。)