记录一下
在做那个无后端的辨别AI图的小游戏时候,通常会遇到一个问题,怎么存这些图片,前端怎么判断这是不是AI图。
这个问题主要考虑到有人可能会去看浏览器请求、看源码,然后就找到快速判断AI图片的作弊办法。比如最不防御的办法就是AI图的文件名后缀是_ai,我当然不希望用这种蠢办法。
存个哈希表可能是一种思路,但哈希表前端也是会暴露出来的,图片规模小的时候肉眼判断也不是不行。而且我觉得查全表有点臃肿。
也想到把文件名命名成_A _B后缀然后AES加密,前端解密后判断A和B也是一种思路。
我最后是有个模糊的想法,然后让Gemini帮我实现出来了。因为这个想法确实很模糊,所以折腾了好久Gemini才理解我的意思。
我的想法是把所有的图片都进行MD5,然后通过一种算法去观察所有图片MD5结果的每一个比特。然后输出一条又一条的判断规则,这样一来只需要储存很少量的数据就能够生成出一套判断逻辑。
Gemini一开始不太理解我的意思,总是想修改图片尾缀去碰撞出特定规律的MD5,虽然这蛮有意思的,但总归有些跑远了。
后来Gemini还是写出了我预想的脚本,生成了一套规则能在42张图片中准确找到21张AI生成的图片。这套规则一共只有12条,涉及到15个比特位。
实现这种需求的办法很多,但是看到AI把自己灵光一现的想法实现出来还是蛮开心的。(虽然中间我有几次差点想骂Gemini,可能是看我以前玩碰撞多了,老想着改我图片去碰撞规则)
不过,只要没有后端就没有秘密,前端再怎么加码都还是会有作弊的办法。
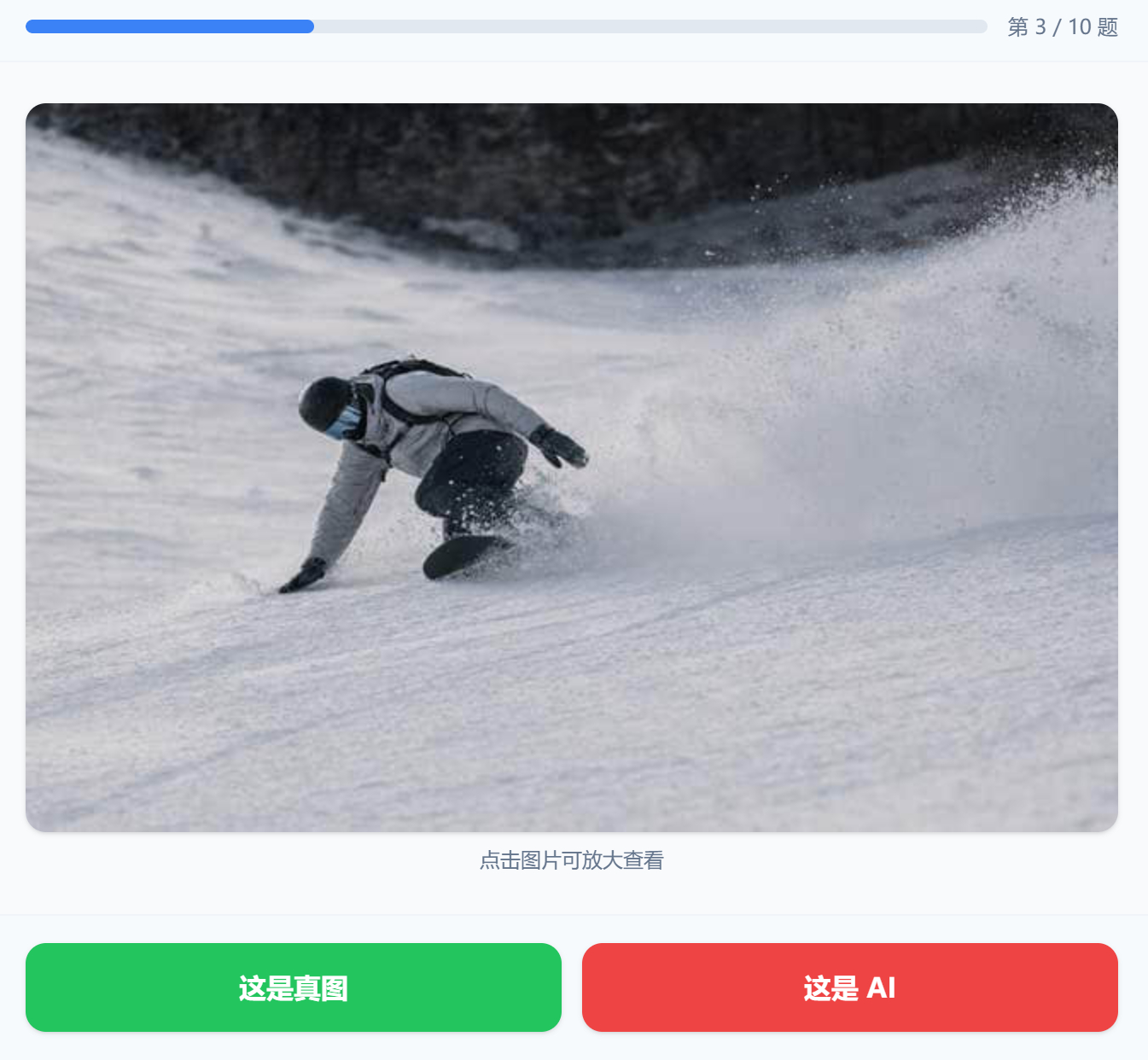
今日新玩具:拟像盲测
real.closeai.moe
点子是偷 @黄健楸 的 https://weibo.com/6083767801/QCsniuNX2 ,昨晚简单实现了Demo,今早稍微优化了一版。
流程是这样的:从 COCO 2017 数据集中获取到真实照片,筛选出640×427的横版图片。经Gemini描述真实照片去生成提示词后由GPT-5.4-Image-2生成AI图片。最后把分辨率压缩至与数据集相同的 640×427。
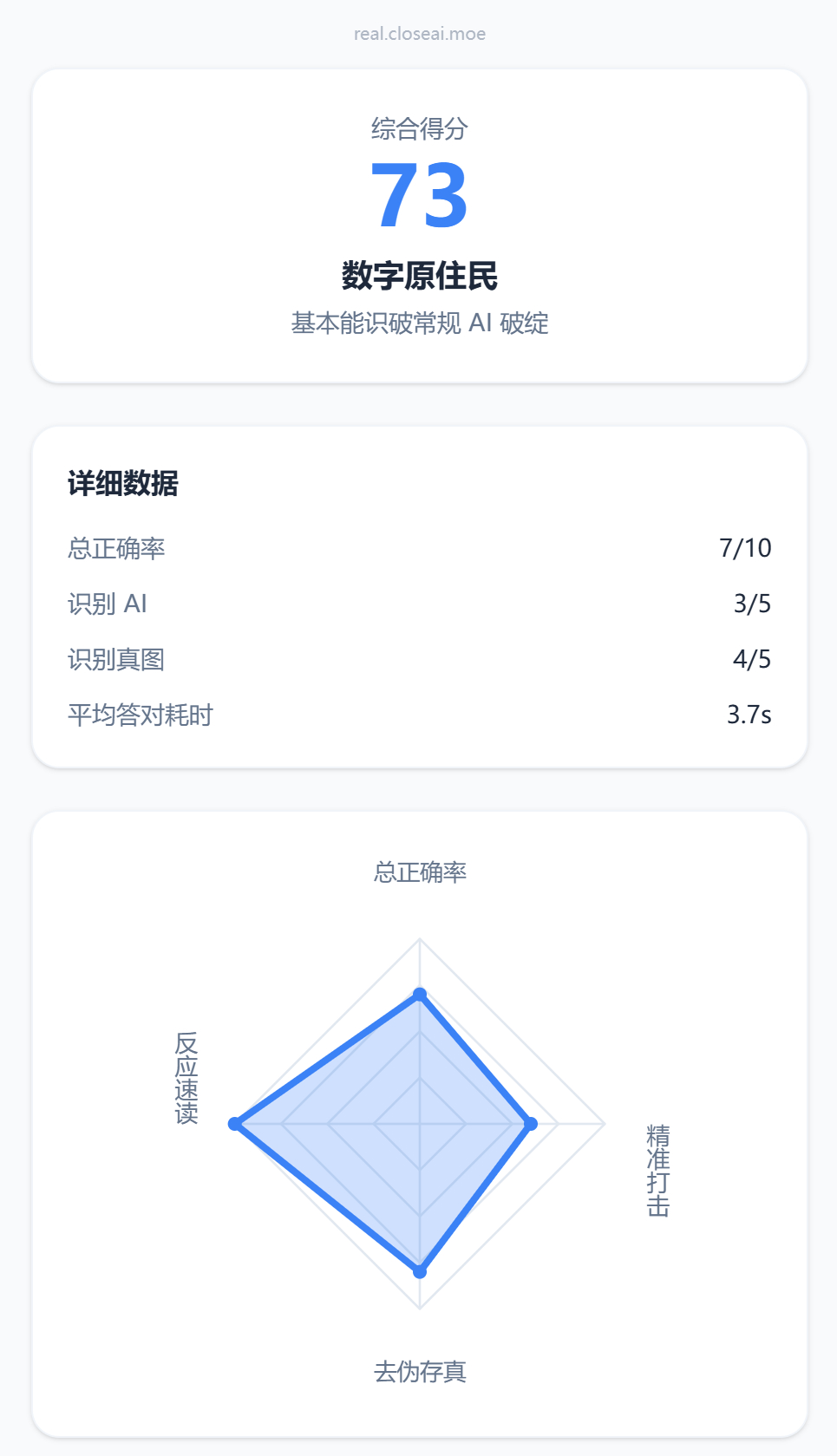
目前题库是202张图片,有一半是GPT生成的。每次游玩会预先加载10张图片,但并不保证这10道题目有一半是AI图,完全随机。然后根据总的正确率、识别出AI、识别出真实图片、作答速度等维度给出一些分数。
多次游玩的结果会合并到首页右上角的“判别档案”。
有朋友反馈图像分辨率比较低,很难识别,这个暂时没有比较好的办法,COCO数据集中的原图就是这个分辨率。但确实如此,分辨率较高更容易暴露AI生图的缺陷,不当做bug的话就算是这个“小玩具”的难度体现吧。
这个小玩具的意义并不是给每个人分辨AI图片的能力做出一种评价,权当是感受一下在特定工作流下生成的AI图片可能会有多大的判断难度。
题库自动去重,不更换浏览器的话玩21次就能确定清空目前题库了。
题库方面更不更新我再观察一下,或许会更换一些原图来源。不过这个生图毕竟还是蛮贵的(我直接调用的API),昨晚挂着生图就花掉20刀了。但我还是要吐槽一下生图不仅不便宜,还很慢,一张图基本需要130秒以上。
大家先体验一下,有什么问题评论区告诉我,我再看着修修。
如果觉得有意思,欢迎转发w