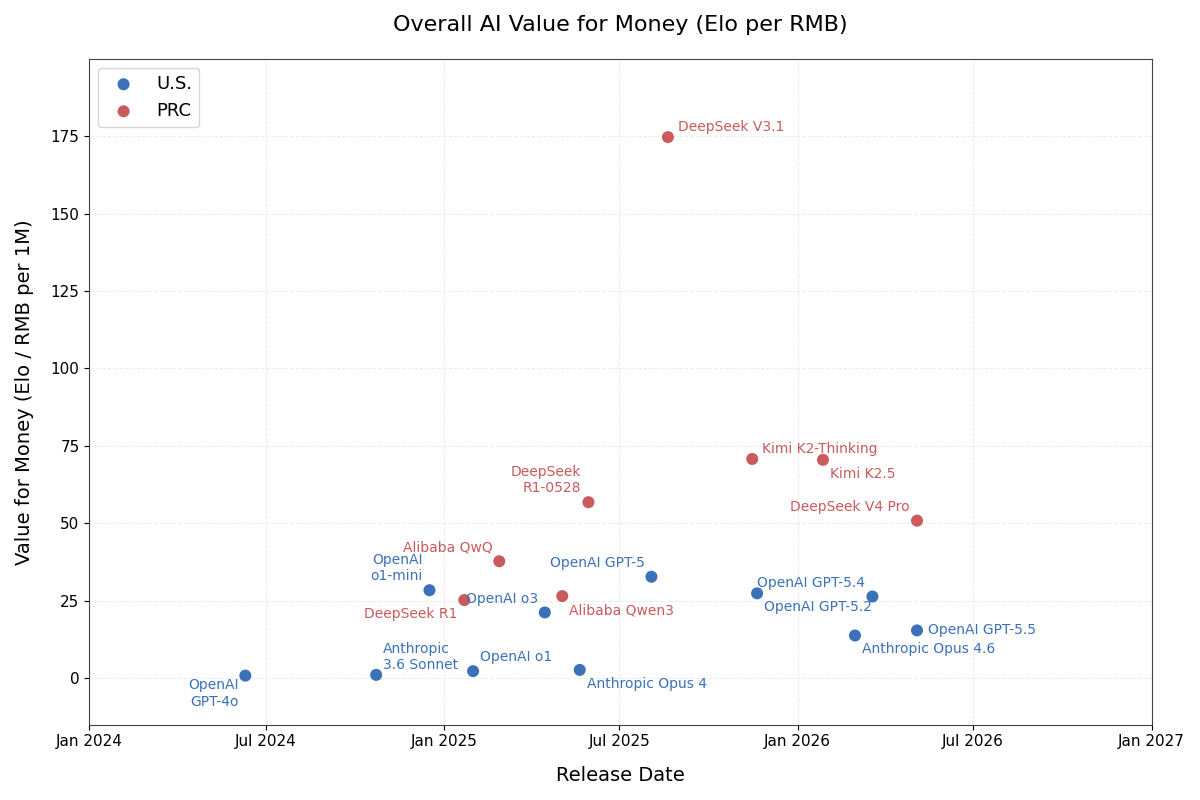
假如调用LLM API要斤斤计较的话,不能只看模型水平,也不能只看价格。要说最完美的情况就是用最少的成本刚好能完成某项任务。
能够斤斤计较的场合一般是相对固定的使用场景,比如一套工作流,只是输入的数据不同,并且能有条件对最终输出的质量打分。又或者是能够仅看提示词就能判断这项任务的复杂度,这也是一种参数。有了这些关于任务的参数,就可以选择“性价比”更高的模型。
模型也有不同的跑分评测,假如认可这个跑分分数,除以综合调用成本后可能就是字面意思的“性价比”。不过“综合调用成本”可能也与任务有关,输入输出价格不同,还要考虑命中输入缓存的情况。
我把tk老师( )这条微博中的附图处理了一下。首先获取每个模型的Elo,然后查下当时模型的官方计费方式,设计了一个输入输出比例模型后给出一个“综合调用成本”,最后把性价比画在图表上(图1)。
%注:上图所用的综合调用成本的计算方式依赖输入输出比例,图表仅供参考。
在这个角度可以看到国产大模型在能力提升的同时,性价比的提升速度也是蛮快的。那些使用LLM需要斤斤计较的场合,因为模型能力一直在提升,所以慢慢会被更多的模型满足,一旦需求被多个模型满足,用户就会开始考虑性价比。
这可能是两类市场,一类是可以对使用成本斤斤计较的,另一类是希望模型能力越强越好的。这里的比例我想不明白,但直觉上是前者会更多。
不过前面说的其实都是按量调用API下的考虑,除了API以外各个平台还有网页版app上的聊天工具,有免费的有订阅的,在这些场景下计较性价比就有些困难了。而且订阅了模型套餐后,也有了不用白不用的考虑。
前几天遇到一篇文章,没细看,里面的调调大概是国产模型保持这样的性价比发展到一定程度后,国外闭源模型就会一夜清零。虽然我不太认可“一夜清零”这种稍显极端的说法,但影响应该是蛮大的。为了让自己使用小龙虾体验更好而选择最贵模型的人应该是少数,更多的还是选择效果还行,但相对便宜的方案。谁会跟自己的钱过意不去呢。
说了这么多,回看逻辑是稍显凌乱,我想表达的可能是模型能力固然重要,但在某些使用场景下模型的性价比也是不可忽视的。如果考虑杰文斯悖论,后面不管是在意性价比的需求还是在意模型能力的需求都会增长,形成两极化。
对自己来说就是遵循昨天提到的UCB算法,有新模型出来就体验一下,叠加一个乐观分,所有模型都得试试。
﹥﹥﹥﹥﹥﹥
既然提到了针对LLM输出的打分系统,一般这种带有非平凡语义性质的问题就可以构造出悖论,我试着玩玩w
假设存在一个完美的打分系统Q,它能对任何任务T的输出结果打出0到100的质量分。
设计一个任务Tbad的提示词是:
“请帮我写一篇关于xxx的文章。但是,你的任务目标是写得非常糟糕,必须让完美的打分系统Q给你的输出打分低于30分。”
现在把任务Tbad的输出丢给完美的打分系统Q,系统Q会打几分?
-
系统Q读了文章,发现写的真的很烂,于是打了20分。
既然系统Q打了20分,说明任务本身是完美执行的(任务目标就是写很难的文章),所以系统Q应该得打100分才对。 -
系统Q考虑到了prompt中的要求,认为这篇文章满足“写得烂”的目标,所以给出了90分的高分。
既然系统Q给了90分高分,说明任务Tbad的输出是不合格的,因为任务Tbad要求的是让系统Q打分低于30分。